How FaMIE works
In this section, we briefly present the most important details of the technologies used by FaMIE.
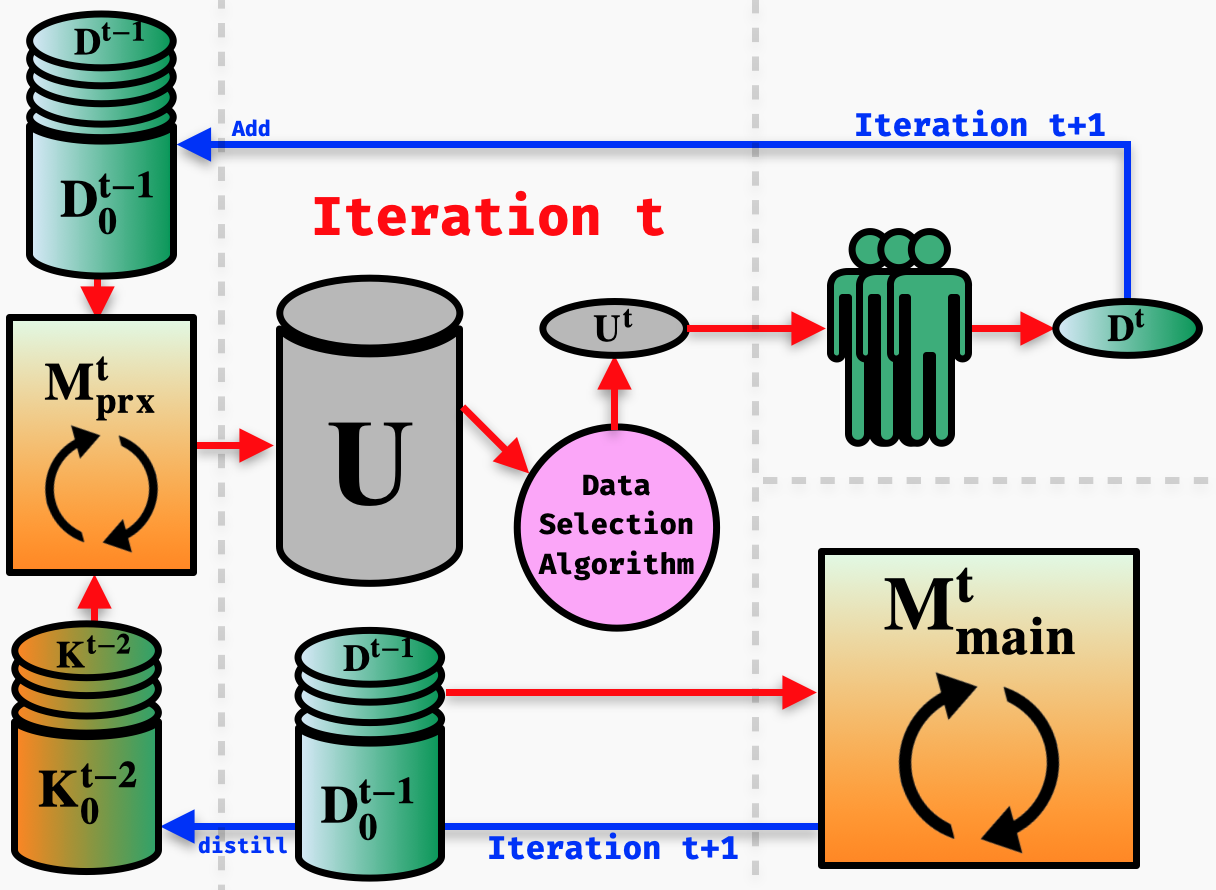
Incorporating current large-scale language models into traditional AL process would dramatically increase the model training time, thus introducing a long idle time for annotators that might reduce annotation quality and quantity. To address this issue without sacrificing final performance, FAMIE introduces Proxy Active Learning. In particular, a small proxy model is used to unlabeled data selection, while the main model is trained during the long annotation time of the annotators (i.e., main model training and data annotation are done in parallel). Given the main model trained at previous iteration, knowledge distillation will be employed to synchronize the knowledge between the main and proxy models at the current iteration.